

Dans une étude récemment publiée dans la revue médicale mensuelle JAMA Ophthalmology, une publication des chercheurs de l'université médicale et dentaire de Tokyo (TMDU) fait état d’un modèle d'apprentissage automatique* développé pour prévisualiser le risque de déficience visuelle à long terme.
« Nous savons que les algorithmes d'apprentissage automatique fonctionnent bien sur des tâches telles que l'identification des changements et des complications de la myopie », explique Yining Wang, un des auteurs principaux de l'étude, « mais nous voulions évaluer la qualité de ces algorithmes sur des prévisions à long terme ».
Pour ce faire, l’équipe a suivi 967 patients japonais au centre clinique avancé pour la myopie du TDMU après 3 et 5 ans. Une base de données a été constituée à partir de 34 variables couramment collectées lors des examens telles que l'âge, l'acuité visuelle actuelle et le diamètre de la cornée.
Les résultats démontrent le potentiel de cette technologie en matière d'évaluation et de surveillance cliniques :
- Grâce au modèle dit de régression logistique**, il est possible de prédire avec précision l'acuité visuelle à 3 et 5 ans ;
- Un modèle de classification binaire*** peut quant à lui prédire et visualiser le risque à 5 ans pour des patients individuels.
Les chercheurs ont ensuite utilisé un nomogramme « pour faciliter la compréhension des patients et pratique pour prendre des décisions cliniques » :
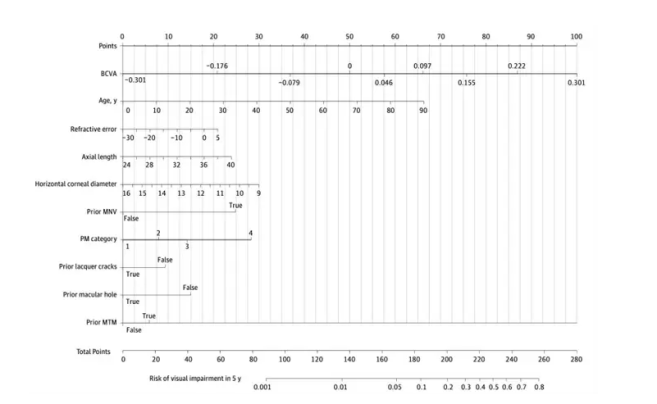
@TMDU
Chaque variable se voit attribuer une ligne d'une longueur qui indique son importance pour prédire l'acuité visuelle. Ces longueurs peuvent être converties en points qui peuvent être additionnés pour obtenir un score final expliquant le risque de déficience visuelle à l'avenir.
* Champ d'étude de l'intelligence artificielle qui se fonde sur des approches mathématiques et statistiques pour donner aux ordinateurs la capacité d'« apprendre » à partir de données.
** En médecine, la régression logistique permet par exemple de trouver les facteurs qui caractérisent un groupe de sujets malades par rapport à des sujets sains.
*** Une des méthodes de classification utilisée pour l’apprentissage automatique.

![[Vidéo] L'association des optométristes de France (AOF) se positionne sur la télémédecine](https://www.acuite.fr/sites/acuite.fr/files/styles/home_slider_video/public/articles/aof_telemedecine_thibaud_thaeron.png?itok=RjIwETsM)